Gradient Descent with Periodic Entrainement on the Loss Surface of Neural Networks:
Consider the entrained system with initial condition \(y_0\) (see [1]): \begin{equation}\label{eq:GDE0} \dot{y}(t)=g(y(t))+\gamma(t)\varphi(t) \end{equation} with \(g:\mathbb{R}^p\rightarrow\mathbb{R}^p\), \(y(0)=y_0\in\mathbb{R}^p\) and \(\gamma(t)=\alpha\beta(t)\) where- \(\alpha\in\mathbb{R}_{\geq 0}\) is the amplitude factor,
- \(\beta:\mathbb{R}_{\geq 0}\rightarrow [0,1]\) the slow periodic function with period \(U\),
- \(\varphi:\mathbb{R}_{\geq 0}\rightarrow [-1,1]^p\) the fast periodic function with period \(T\)
To get the code source: Click Here
Numerical Example 1:
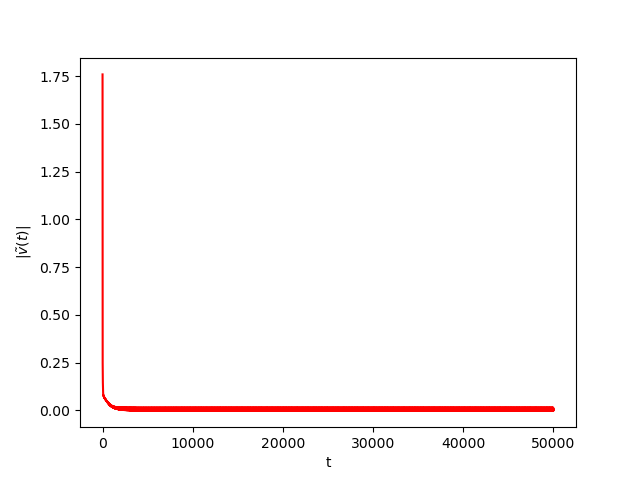
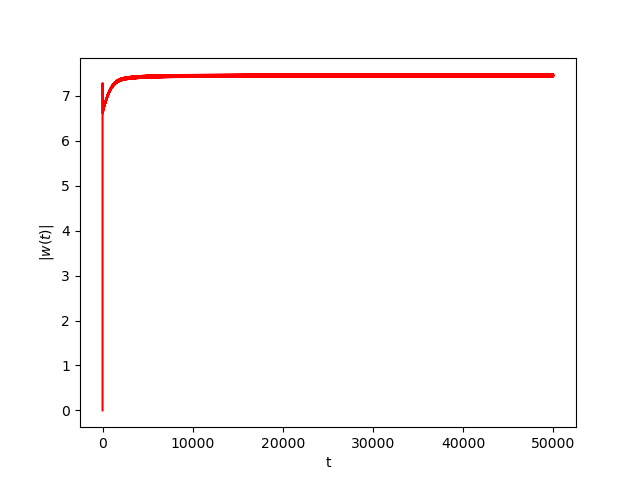
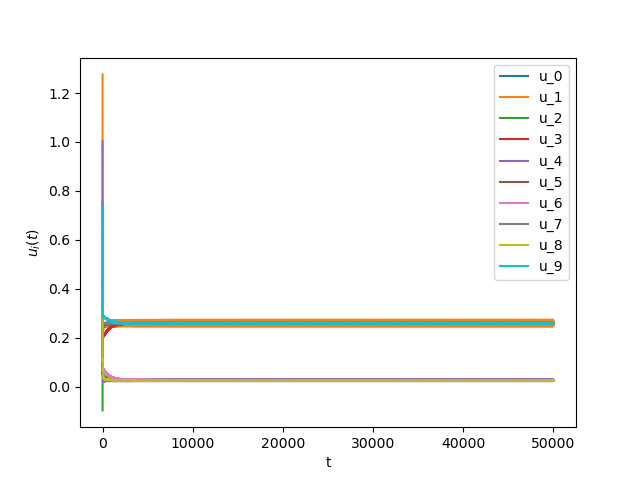
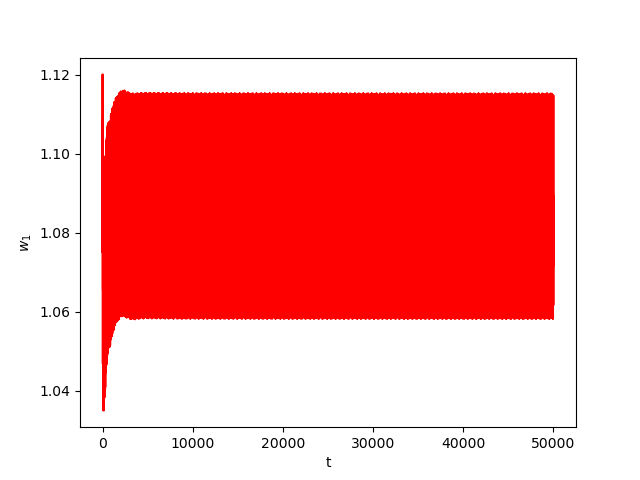
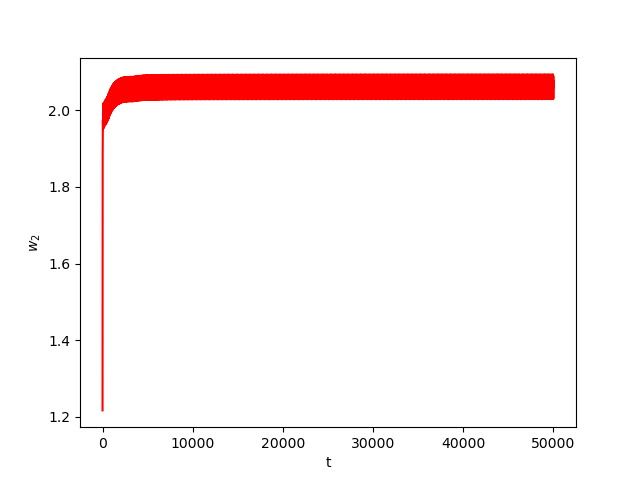
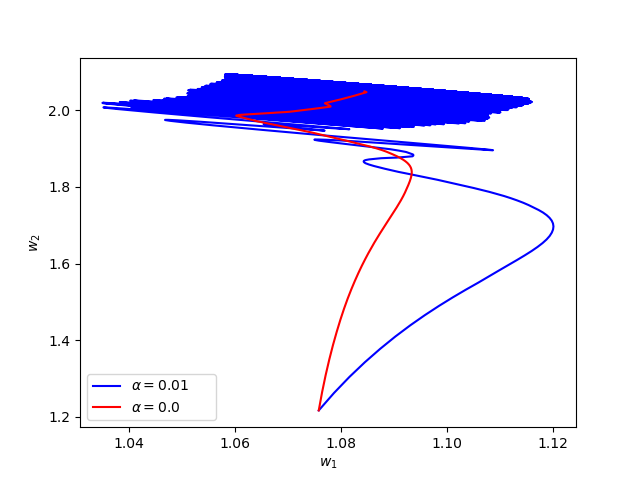
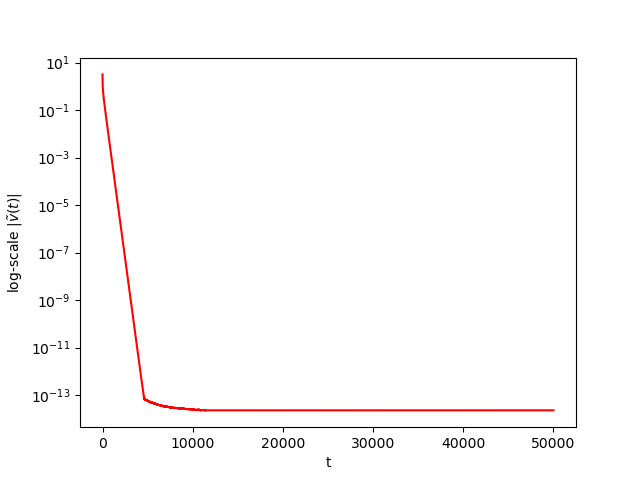
We consider The training has been conducted using \(n=10\) data points, \(m=20\) hidden nodes and \(d=3\). We take \(h=0.15\), \(\varphi=\cos(\frac{t}{2})\) and \(\alpha=0\). The initial conditions and the initial first layer weight vector \(w^r\) are picked randomly.Results:
Numerical Example 2:
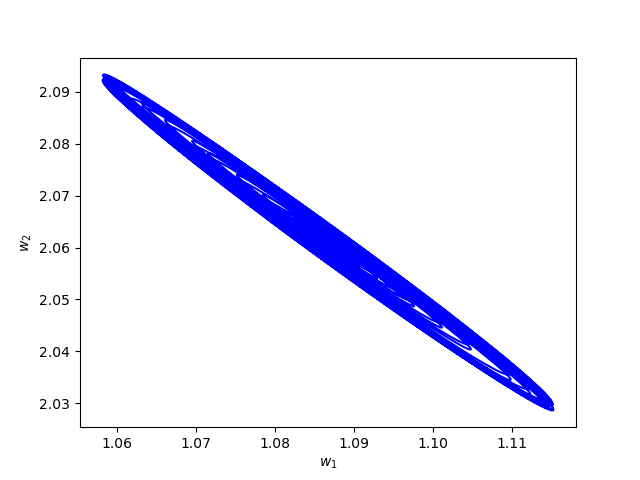
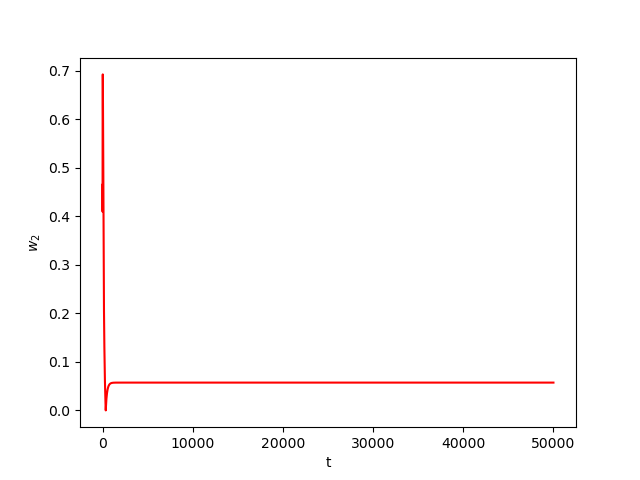
Now we consider the same example but with \(\alpha=0.01\) and \(\beta(t)\in [0,1]\) is a triangular signal of period \(U=2.5T=10\pi\).Results:
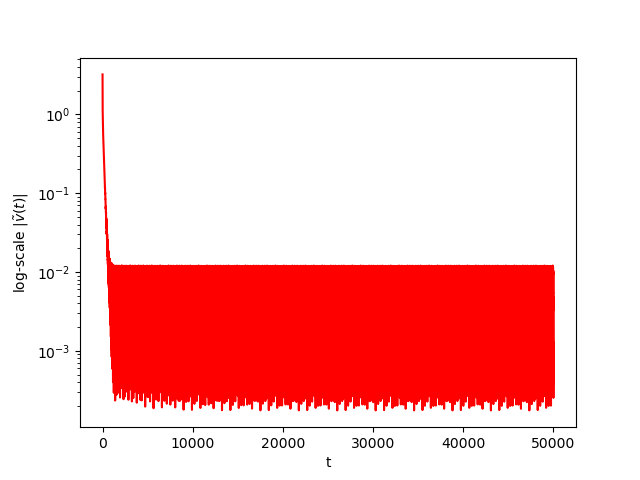
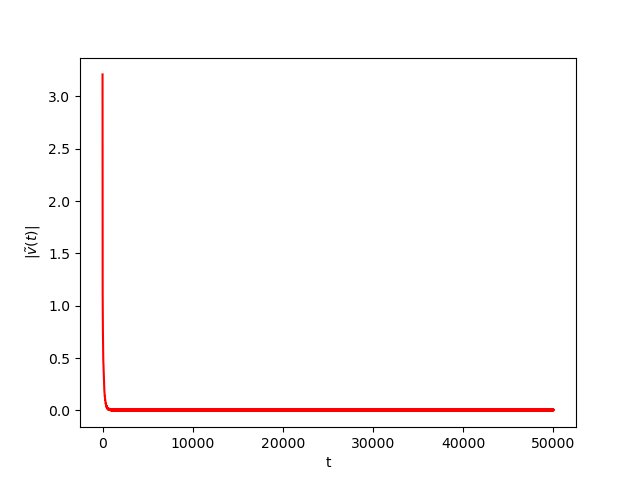
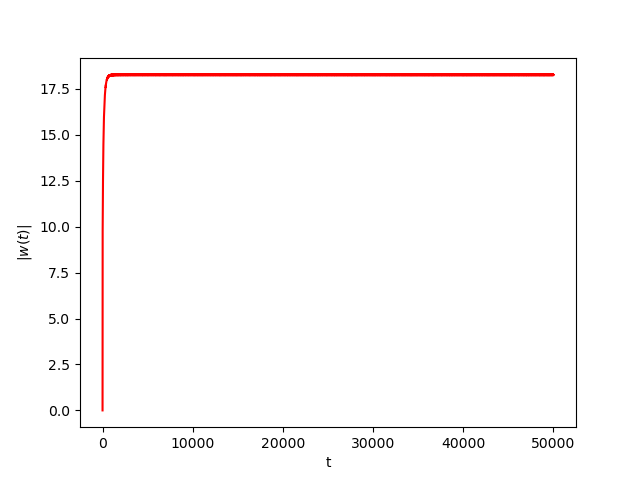
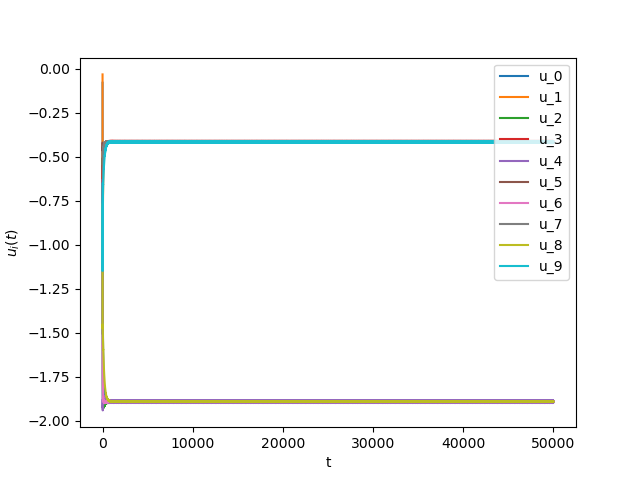
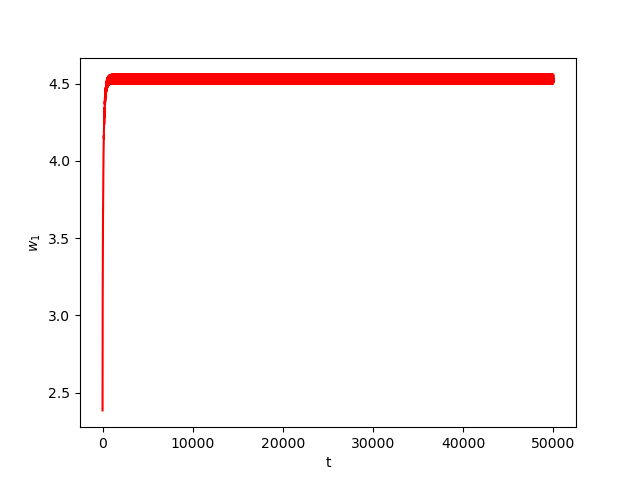
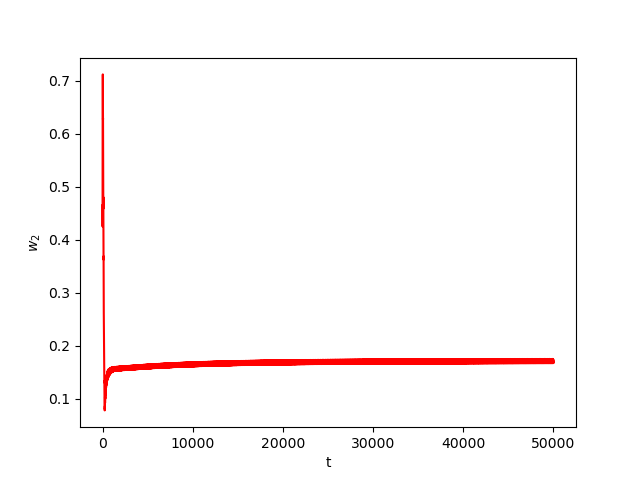
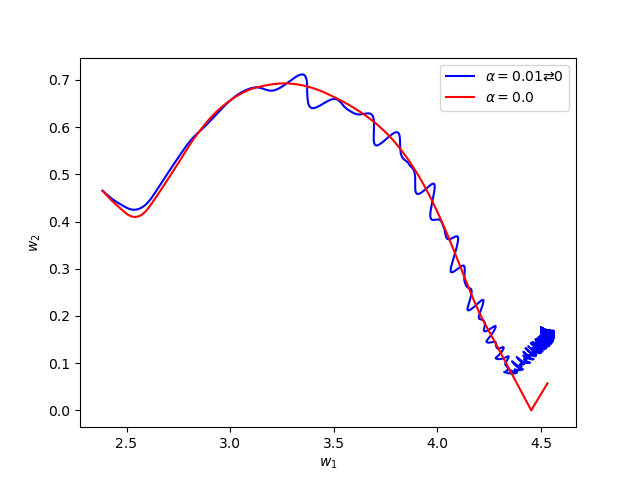
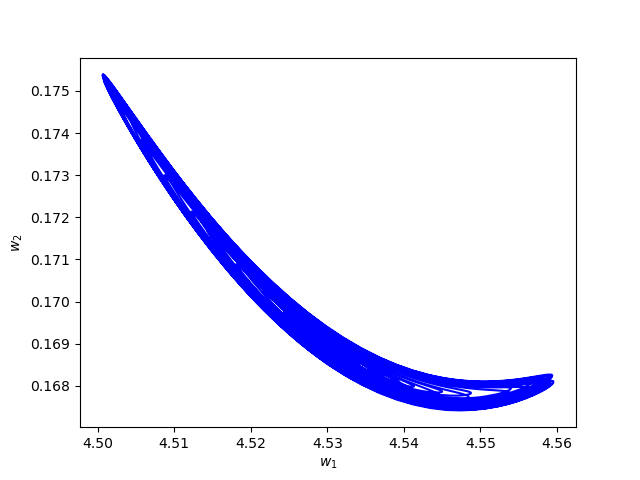
Numerical Example 3:
Now we consider the same example but with \(\alpha=0.05\) and \(\beta(t)\in [0,1]\) is a triangular signal of period \(U=2.5T=10\pi\).Results:
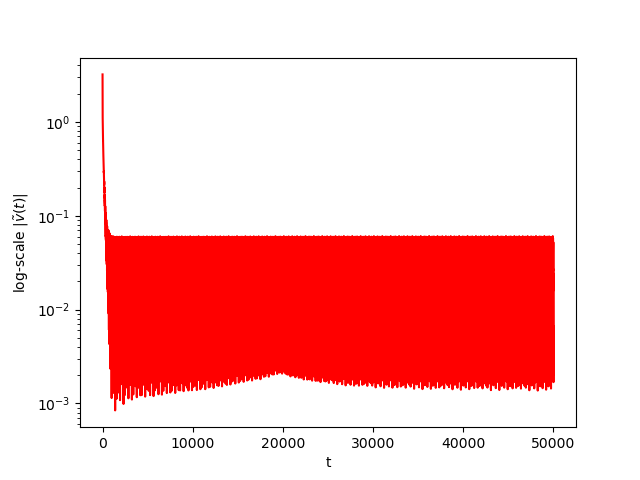
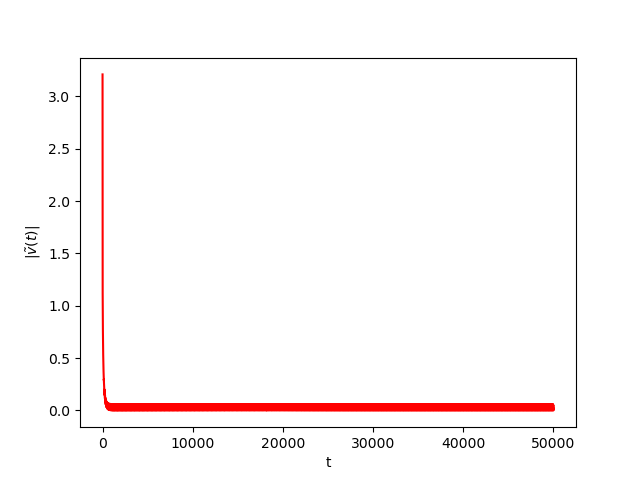
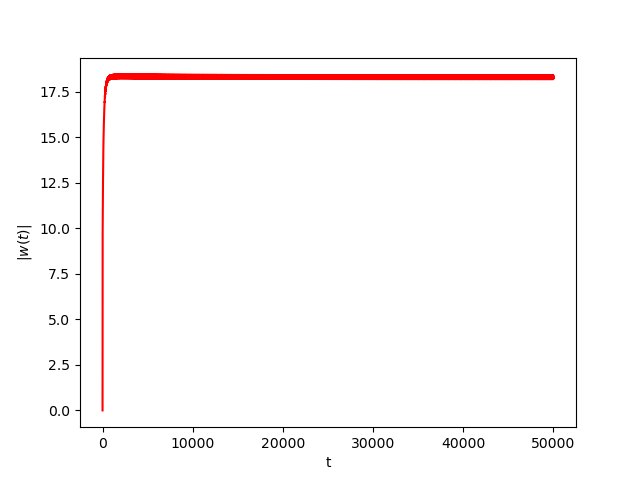
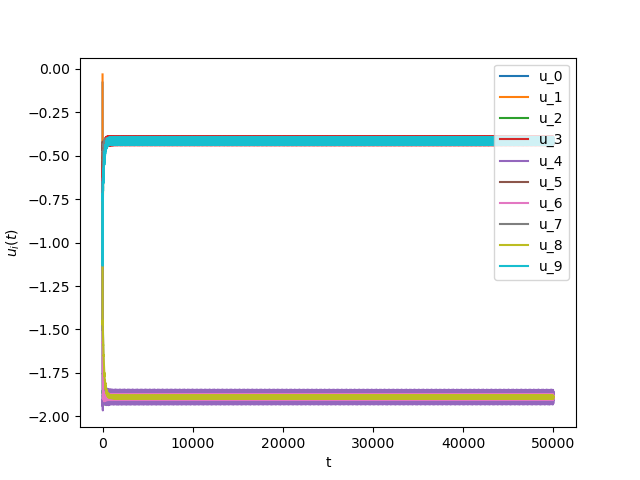
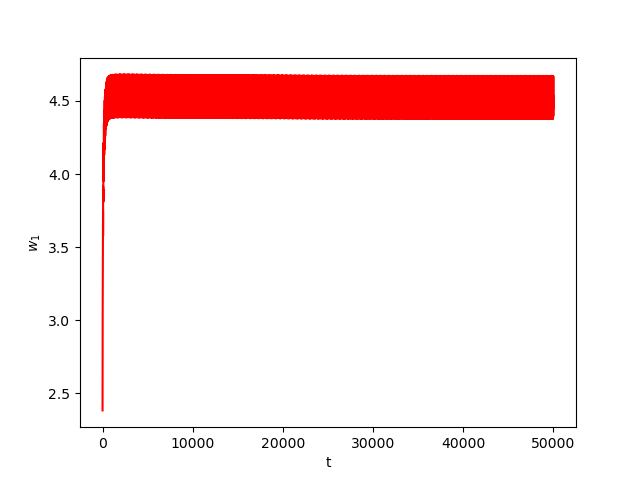
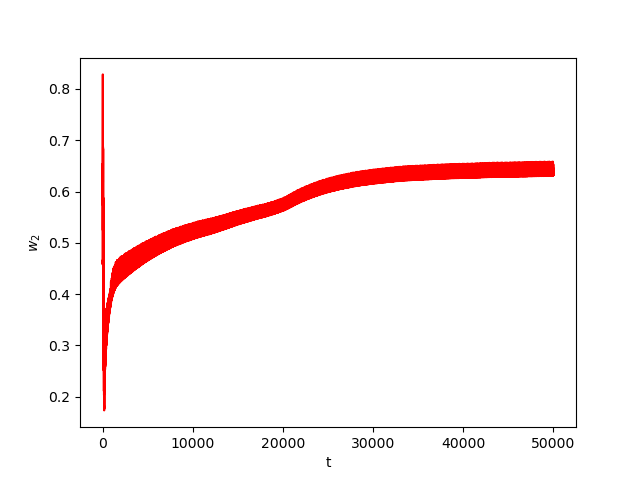
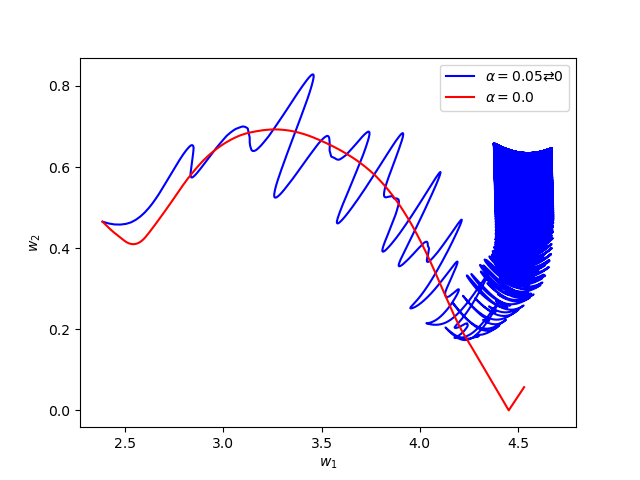
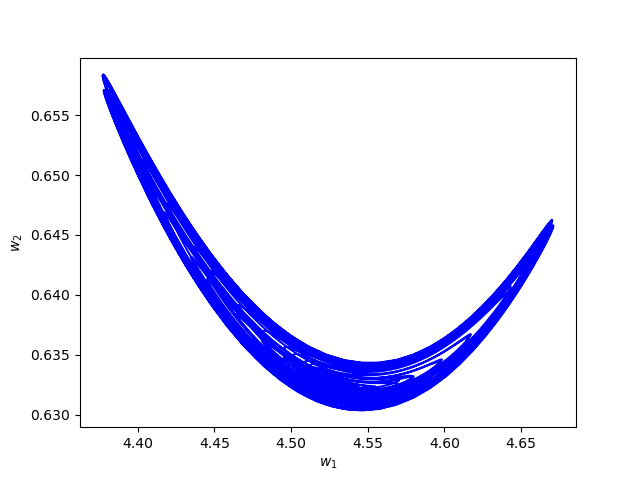
Numerical Example 4:
Now we consider the same example but with \(\alpha=0.07\) and \(\beta(t)\in [0,1]\) is a triangular signal of period \(U=2.5T=10\pi\).Results:
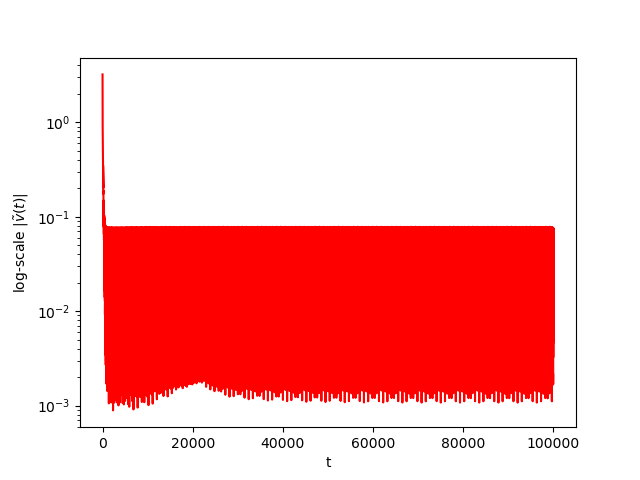
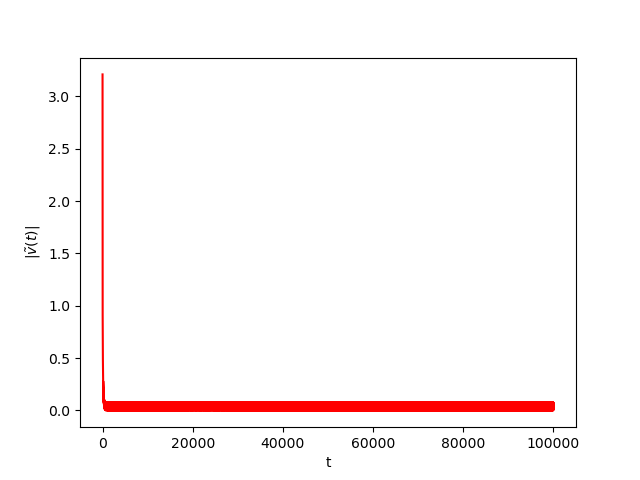
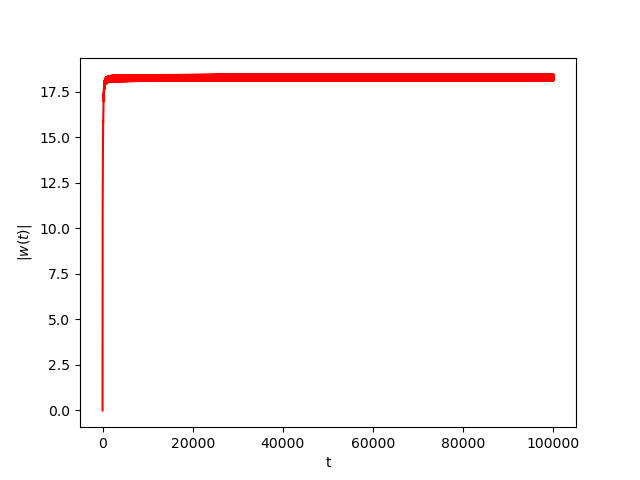
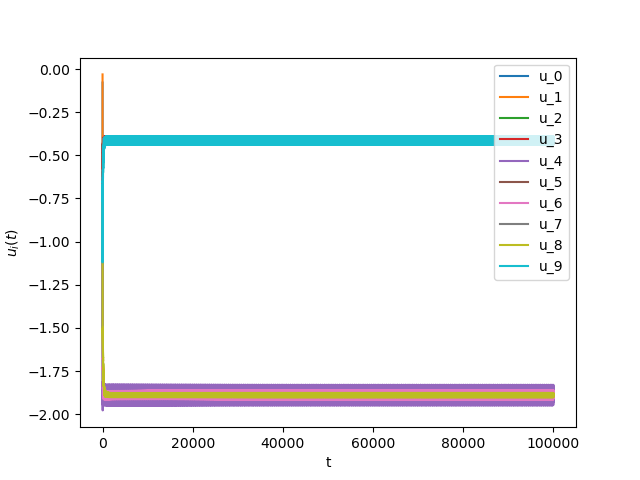
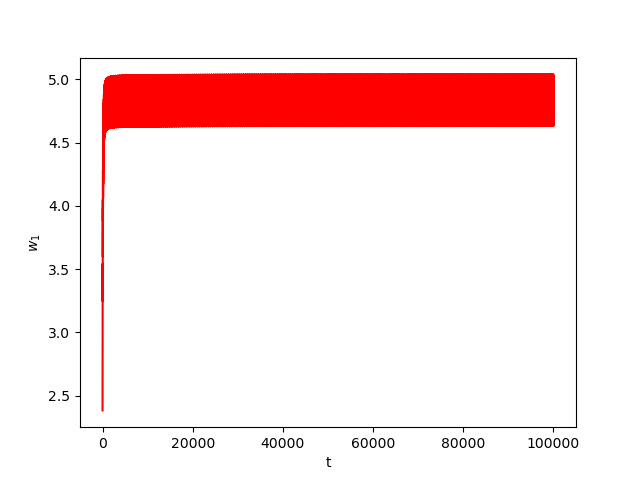
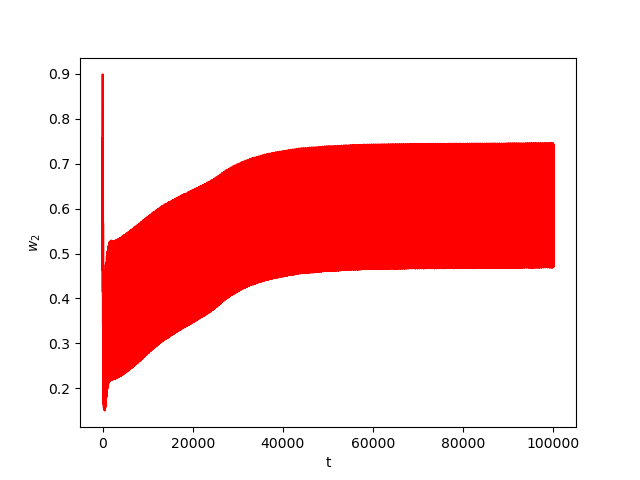
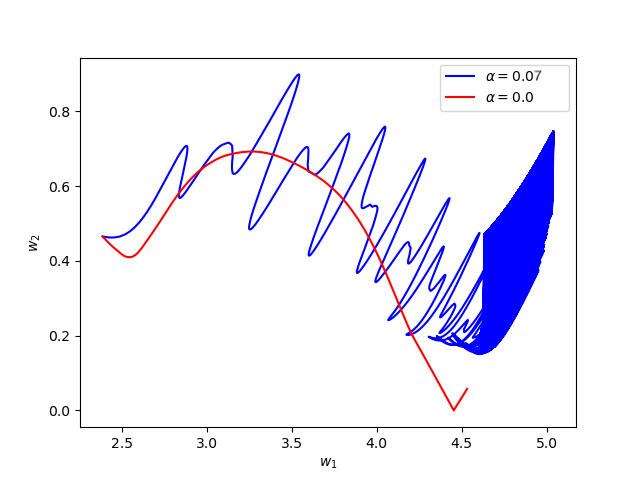
Numerical Example 5:
We consider the same example but with differant inital conditions, \(\alpha=0.01\) and \(\beta(t)\in [0,1]\) is a triangular signal of period \(U=2.5T=10\pi\).Results: