![]()
3rd Conference
The Evolution of Language
April 3rd - 6th , 2000
Abstracts
|
|
3rd Conference Abstracts |
![]()
CNTS
UIA - University of Antwerp
depauw@uia.ac.be
daelem@uia.ac.be
In this paper, we describe work in progress on the GRAEL (GRammar Adaptation, Evolution and Learning) environment, in which we aim to develop a suitable environment in which natural language grammars can interact and co-evolve according to underlying principles of genetic programming. From an engineering point-of-view, the GRAEL environment offers a grammar optimisation method that will help alleviate problems of grammar coverage and sparse data. The main focus is however more theoretical in nature: the modularity of the GRAEL system allows us to investigate the dynamics of grammar evolution and adaptation, as well as offering a wide range of extensions for future research.
The problematic domain of syntax has been of particular interest to NLP-researchers, prompting them to develop syntactic parsers that range from attempts to translate Chomskian insights into a computational context to highly efficient implementations of rather ad hoc grammatical systems.
So far, however, little syntactic ground has been covered in the evolutionary computing paradigm. With the notable exception of Losee’s LUST system [Losee1995], in which an information retrieval system is powered by genetically evolving grammars, most GA syntactic research has focussed on non-linguistic data.
Smith and Witten [Smith and Witten 1996] use a Genetic Programming-related algorithm to adapt a population of hypothesis grammars towards a more effective model of language structure. Smith and Witten use tree structures as their syntactic representation, with nodes labelled as either AND or OR, which can be interchanged during mutation. Fitness of an individual is measured by counting its grammar size and its ability to parse test strings.
Wyard [Wyard 1991] and Blasband [Blasband 1998] also use Genetic Programming to induce and optimise grammars.
Closely related to this line of work, is Antonisse’s effort [
Rawlins 1991] in which grammar-based crossover is implemented, a feature lacking in [Smith and Witten1996]. Crossover occurs by randomly splitting a sentence into 2 sentence fragments and interchanging them with 2 fragments of another sentence.Antonisse tries to develop a grammar-based genetic algorithm for all types of grammars, rather than to investigate the behaviour of linguistic grammars in an evolving context, Smith and Witten’s linguistic analysis of the generated data suffers from the fact that their linguistic representation is too weak to offer any insight in this matter. Losee’s LUST-system, which is powered by genetically evolving grammars, is very much applied to its information retrieval task and does not offer any theoretical insights on the dynamics of grammar adaptation itself.
The GRAEL environment is explicitly geared towards the goal of investigating the behaviour of grammars for natural language in an evolutionary context. Presented here is the grammatical backbone of the environment, as well as the general methodology, prototypical results and future extensions to this line of research.
Taken from the field of statistical parsing, Data Oriented Parsing (DOP, [Bod 1998]) fits the evolutionary computing paradigm very well because of its emphasis on substitution of parts of syntactic trees (so-called substructures), representing derivations, and its absence of an explicit abstract rule-based grammar. Parsing a sentence with the DOP-model involves finding the most probable combination of substructures, stored in a treebank, induced from an annotated corpus.
In the GRAEL-environment, the principles of the DOP-model are translated as follows: an annotated treebank i.e. a collection of pre-parsed sentences (currently ATIS [Santorini 1993]), is distributed over a number of individuals. An individual therefore consists of a number of tree structures, representing the language experience of a language user. The grammars are used to power a memory-based implementation of the DOP-model [De Pauw 2000] for parsing:
A weighted combination of metrics expresses an individual’s fitness:
efficiency of the grammar: the number of nodes in an individual’s "forest" (collection of trees), translating the notion that a smaller grammar is a better grammar
the accuracy with which an individual’s forest is able to parse a held-out set of test strings
language games (methodology/concept borrowed from ARTI-research [Steels 1996]):
the ability with which the grammar induced from an individual’s forest is able to parse another individual’s sentences (understanding)
the success-rate with which another individual is able to parse the individual’s generated sentences (understandability)
Neo-Darwinism is introduced by preferring fitter individuals for "reproduction". Reproduction currently does not create new individuals as such, but extends an individual’s knowledge through crossover and mutation operations.
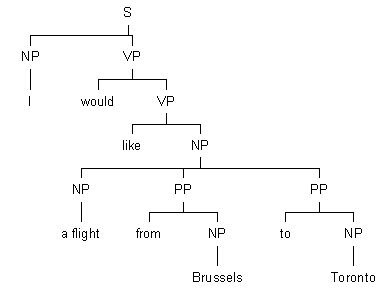
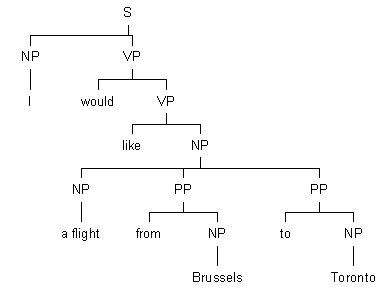
One individual is randomly selected for "reproduction". Crossover occurs when a random node in one of the tree structures of this individual is exchanged for a random node (carrying the same label) of another individual. For example:
|
sentence n1 (individual 1) |
sentence n2 (individual 2) |
|
|
|
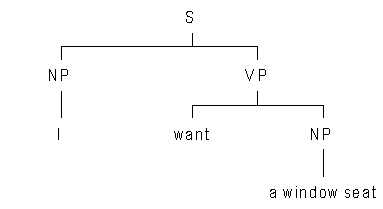
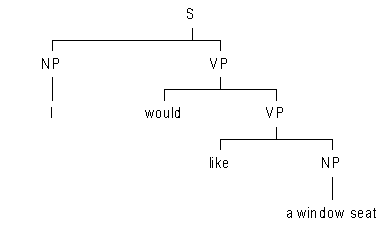
Individual 1 may now exchange the NP a flight from Brussels to Toronto with individual 2’s NP a window seat, yielding the following two new tree structures (sentences) for the respective individuals:
|
sentence n1’ (individual 1) |
sentence n2’ (individual 2) |
|
|
|
In the above example, two new grammatical sentences have been generated. Exchanging VP-nodes however would yield the sentence I want like a window seat from Brussels to Toronto. The crossover operation yields sentences, varying in grammaticality. Fitness functions (2) and (3) will express a preference for individuals containing grammatical tree structures. Furthermore, when an individual’s forest reaches a certain threshold, it is pruned using probability and entropy of the tree structures as relevant metrics.
[De Pauw 2000] has also reported problematic parsing on the NP-level with the ATIS-corpus. When using a blind-testing method (testing on held-out test data), we notice that most of the unparsable sentences are problematic on the lowest NP-level, i.e. NP’s only consisting of lexical items. An NP like "Flight 447 A K nine" would have the following NP-structure (NP ® noun number noun noun number), a constituent understandably not found in the training data.
Through mutation, items (i.e. branches) are added or deleted from NP-structures in the constituents. This causes a lot of grammatical overhead in the environment, but the new structures are maintained or discarded, using the above-mentioned fitness functions.
The initial corpus-based experiments are based on the very small ATIS-corpus. The grammars distributed over the individuals are therefore extremely limited in generative power. The "reproduction" and interaction with other individuals, however, extends the grammar very fast and adapts it to a specific use, be it understanding other individuals, or parsing the test set. We will present how well the environment is able to do just that and we will present how a faulty grammar can improve itself by interacting with other (faulty) grammars in an evolutionary context.
We also evaluate this approach by comparing the accuracy on the held-out testset of the "full" grammar (i.e. the grammar induced from ALL individuals) to the accuracy of the grammar of the fittest individual. When we limit "reproduction" to crossover, we notice a tendency in the individuals to level around 250 rules (from a total rules of 2600 rules), indicating that the full corpus contains many marginal rules not needed for efficient and accurate parsing. The mutation operator rapidly extends grammar size at the cost of parser efficiency, yet the desired effect of grammatical smoothing takes place with some individuals developing grammars that parse sentences that the full grammar was not able to.
More theoretically, we will look at the evolution and intricacies of each individual’s syntactic component for particular (combinations of) fitness-functions. We will describe what a grammar looks like when it’s been genetically improved for efficiency (fitness function (1)), for accuracy (2), understanding (3a) and understandability (3b).
A proper implementation of reproduction (in which new individuals are created) will be added to the GRAEL environment. Also, the limitation on crossover nodes (cf. only nodes with the same label can be exchanged) will be relaxed. Mutation will be extended to other categories than NP.
With respect to the data, we will be using other corpora in the GRAEL-environment, as well as combining different corpora, in order to investigate notions of understanding and understandability between individuals made up of tree structures from different corpora.
The corpus-based experiments however only serve as a first test drive of the GRAEL environment and the main focus in future work will be on the unsupervised emergence of grammatical principles. A grammar development module will serve as a bootstrap for the GRAEL framework, so that given a set of random strings, a grammatical systems can be created which will evolve using the principles mentioned above.
The current corpus-based experiments serve the initial purpose to understand the mechanics of grammatical evolution, as well as give us pointers for the above-mentioned extensions to the GRAEL-environment
[Antonisse 1991] Antonisse, H.J.. 1991. A Grammar-Based Genetic Algorithm. In [Rawlins 1991]
[Blasband 1998] Blasband, M. 1998. Gag genetic algorithms for grammars. Technical Report Compuleer
[Bod 1998] R. Bod, 1998. Beyond Grammar: An Experience-Based Theory of Language, CSLI Publications, Cambridge University Press. 184pp.
[De Pauw2000] De Pauw, G. 2000. Probabilistic Parsers - Pattern-matching aspects of Data-Oriented Parsing [in Dutch]. Antwerp Papers in Linguistics (forthcoming)
[Losee11995] Losee, R.M. 1995. Learning syntactic rules and tags with genetic algorithms for information retrieval and filtering: An empirical basis for grammatical rules. In Information Processing and Management.
[
Rawlins 1991] Rawlins, G.J.E. 1991 Foundations of genetic algorithms. M. Kaufmann: San Mateo, Calif.,1991[Smith and Witten 1996] Smith, T.C. and I.H. Witten, 1996. Learning Language using genetic algorithms. In Connectionist, statistical and symbolic approaches to learning for natural language processing.
[Santorini 1993] Santorinit et al: Building A Large Annotated Corpus Of English: The Penn Treebank. Computational Linguistics, Vol. 19, 1993.
Steels, L. (1996)
Synthesising the origins of language and meaning using co-evolution, self-organisation and level formation. In: Hurford, J., C. Knight and M. Studdert-Kennedy (ed.) (1997) Evolution of Human Language. Edinburgh Univ. Press. Edinburgh.[Wyard 1991] Wyard, P. 1991. Context free grammar induction using genetic algorithms. In Proceedings of the 4th International Conference on Genetic Algorithms, 514-518.
![]()
Conference site: http://www.infres.enst.fr/confs/evolang/