Algorithme de Dijkstra
Summary
Description de l'algorithme
Entrée : Un graphe pondéré + un sommet initial
Sortie : Pour chaque sommet, la distance la plus courte du sommet initial
Initialisation
Distance infinie pour tous les sommets sauf le sommet initial : on lui met 0.
À chaque étape
À chaque étape, on considère le sommet non visité de plus faible distance connue (sommet courant) :
- On parcourt tous ses voisins et on met à jour la distance connue avec la nouvelle distance que si elle est meilleure.
- On le marque comme déjà visité.
Graphe utilisé en exemple
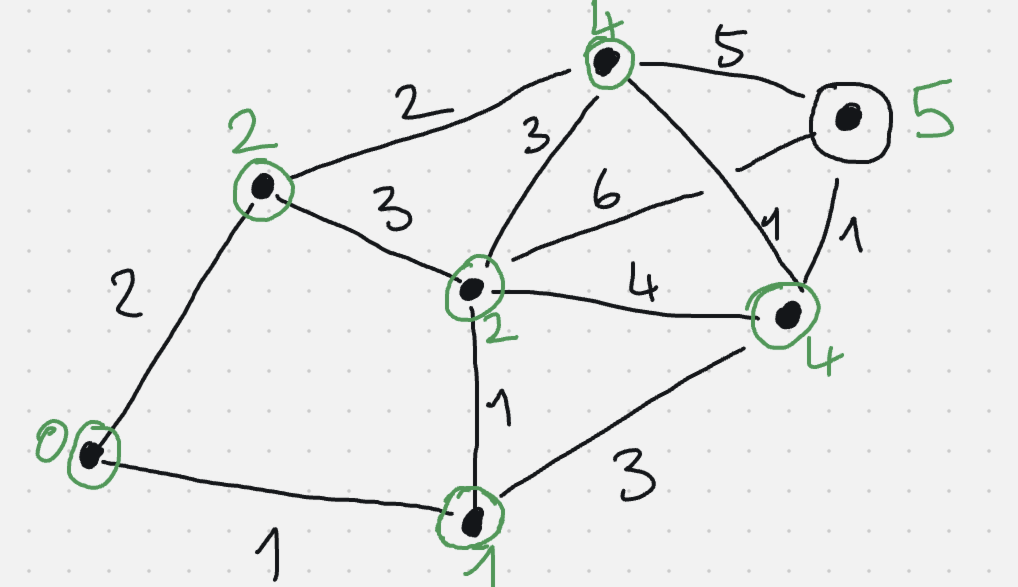
Code
Je veux bien que tu m'envoies ton code quand t'as le temps.
Matrice d'adjacence pondérée
Pour écrire le programme, nous avons utilisé la matrice d'adjacence pondérée : aulieu d'avoir des
float("inf")
La distance entre un sommet et lui même est
Entraînement
Le mieux c'est que tu refasses toi-même l'algo crayon papier sur quelques exemples:
Tu peux en profiter pour appliquer au crayon et au papier, le parcours en profondeur et le parcours en largeur.
N'ignore pas ces exercices qui peuvent parraître très simples, car ils te permettent de vraiment bien retenir (et bien comprendre) les algos.
Un autre exercice sur les graphes
Exercice : Modélisation du seuil de percolation sur un réseau hexagonal
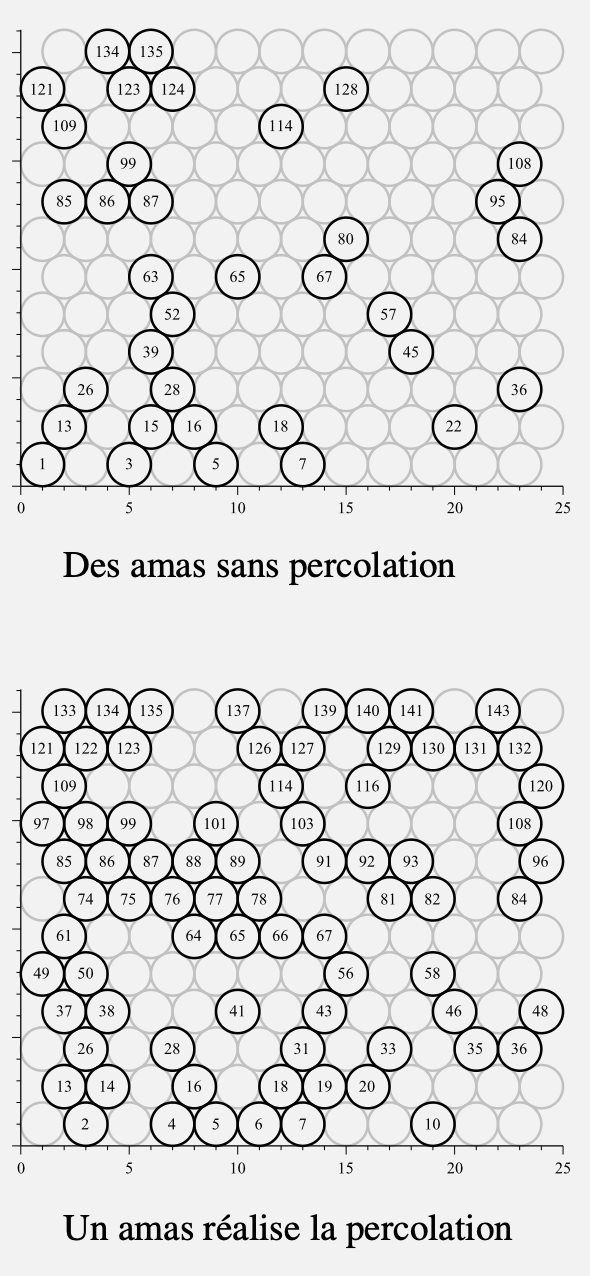
Dans cet exercice, nous allons explorer le concept de percolation sur un graphe représentant un pavage hexagonal en 2D. La percolation est un phénomène probabiliste où des sites (ici, des sommets) sont occupés aléatoirement avec une probabilité
Nous modéliserons un graphe sur une grille de taille 12×12 (sommets
Le pavage hexagonal est défini comme suit :
- Chaque sommet
a des voisins potentiels basés sur sa position. - Pour un sommet intérieur non sur un bord :
- Voisins : droite
, gauche , - Haut : si
est pair, et ; si est impair, et . - Bas : si
est pair, et ; si est impair, et .
- Voisins : droite
- Sur les bords, seuls les voisins valides (dans la grille) sont considérés.
- Exemple : Pour
conducteur, voisins : et (si conducteurs).
Nous subdiviserons l'exercice en plusieurs questions pour construire progressivement les fonctions nécessaires. Utilisez des structures de base Python (listes, dictionnaires, boucles, conditions) et le module random pour les probabilités.
Question 1 : Générer la liste de tous les sommets
Écrivez une fonction generer_sommets(n) qui prend en paramètre la taille
Exemple d'appel :
sommets = generer_sommets(12)
print(len(sommets)) # Devrait afficher 144
Question 2 : Déterminer les voisins potentiels d'un sommet
Écrivez une fonction voisins_potentiels(sommet, n) qui prend un sommet
- Utilisez les règles du pavage hexagonal décrites ci-dessus.
- Vérifiez que chaque voisin potentiel est dans les bornes
.
Exemple :
print(voisins_potentiels((0, 0), 15)) # Devrait retourner [(1, 0), (0, 1)]
print(voisins_potentiels((6, 6), 12)) # Devrait retourner 6 voisins pour un sommet intérieur
Question 3 : Générer les sommets conducteurs
Écrivez une fonction generer_conducteurs(sommets, p) qui prend la liste des sommets et une probabilité random.random().
Exemple :
import random
conducteurs = generer_conducteurs(generer_sommets(12), 0.5)
print(len(conducteurs)) # Environ 72 (aléatoire)
Question 4 : Construire le dictionnaire d'adjacence
Écrivez une fonction construire_graphe(conducteurs, n) qui prend l'ensemble des conducteurs et la taille
- Les clés sont les sommets conducteurs.
- Les valeurs sont des listes de voisins conducteurs (utilisez
voisins_potentielspour filtrer).
Exemple :
graphe = construire_graphe(conducteurs, 12)
print(graphe.get((0, 0), [])) # Liste des voisins conducteurs de (0, 0), si (0, 0) est conducteur
Question 5 : Vérifier la percolation (du bas vers le haut)
Écrivez une fonction percolation_bas_haut(graphe, n) qui vérifie s'il existe un chemin connecté du bas (ligne
- Utilisez une recherche en largeur (BFS) ou en profondeur (DFS) pour explorer à partir de tous les sommets conducteurs en bas (
). - Retournez
Truesi au moins un sommet en haut () est atteignable, sinon False. - Utilisez une file (queue) pour BFS, et un ensemble pour les visités.
Exemple d'implémentation esquissée :
from collections import deque
# "deque" signifie "file" en anglais
# permet d'avoir .popleft() qui n'existe pas par défault sur les listes
def percolation_bas_haut(graphe, n):
# Sommets de départ : conducteurs avec j=0
departs = [sommet for sommet in graphe if sommet[1] == 0]
if not departs:
return False
visités = set()
file = deque(departs)
visités.update(departs)
while file:
courant = file.popleft()
if courant[1] == n-1: # Atteint le haut
return True
for voisin in graphe.get(courant, []):
if voisin not in visités:
visités.add(voisin)
file.append(voisin)
return False
Question bonus : Estimer le seuil de percolation
Écrivez un script principal qui simule 100 fois le processus pour différentes valeurs de
Exemple de script :
n = 12
simulations = 100
for p in [0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7]:
succes = 0
for _ in range(simulations):
sommets = generer_sommets(n)
conducteurs = generer_conducteurs(sommets, p)
graphe = construire_graphe(conducteurs, n)
if percolation_bas_haut(graphe, n):
succes += 1
print(f"Pour p={p}, proportion de percolation : {succes / simulations}")